这两天都在讨论 Cloudflare 的安全事故 Cloudflare outage on November 18, 2025,我也写点自己的想法。
这个事故当然引起的范围特别广,我当时正在用 ChatGPT,突然再打开总是提示正在加载,我还以为是自己的 VPN 出了问题,第二天起来才知道 Cloudflare 跪了好久。
没多久 Cloudflare 就发出来了一个非常详细的事故说明。我对里面的场景非常熟悉,因为我之前因为类似的原因把大疆的大部分流量都给搞挂了,具体请看谈谈工作中的犯错中的配置错误。
这次事故里 Cloudflare 给出了一段 Rust 代码,所以讨论自然会集中在 Rust 上。但把事故归咎于 Rust 本身就不太合理。从他们的场景来看和我之前在 Kong 上做流量分发是非常类似的,无非是这里他们使用了机器学习的技术来判断一个流量是否为恶意请求,而文中所说的 features 文件是训练好的模型数据。
根本原因是数据库的权限更改,导致查询出来的 features 是有重复的,size 变成期望的两倍。而这个错误的配置通过自动同步机制会同步到全球各个节点。每个节点会有一个 bot 模块,根据 features 去计算是否拦截请求,可以想象这是个典型的机器学习分类问题,比如带有什么特征的 HTTP agent、或者是请求的 payload 之类的这些特征综合考虑来计算。这个 Bot Management具体内容可以参考其产品说明。
那么如果 features 坏了,这个机器学习模块 bot 能否正常工作?答案是不行的,这点文章已经说明:
Both versions were affected by the issue, although the impact observed was different.
Customers deployed on the new FL2 proxy engine, observed HTTP 5xx errors. Customers on our old proxy engine, known as FL, did not see errors, but bot scores were not generated correctly, resulting in all traffic receiving a bot score of zero. Customers that had rules deployed to block bots would have seen large numbers of false positives.
事故发生的时候新老组件都有同时在运行,两个组件在这种场景下都无法正常工作,只是错误呈现方式不同。这也解释了我当时用 ChatGPT 给出的浏览器错误是一个拦截错误。
所以这里,unwrap 其实已经算是整个错误的最后一环了。试想一下如果不 unwrap 无非是这几种场景:
- 因为 FL2 是内存受限的,需要预先分配好内存,最大 limit 本来就只能 load 200 个 feature 的配置,现在尺寸超过了,继续 load 应该就是 OOM 错误,不可恢复。
- load 到最大 limit 的时候停止,这时候不确定整个 feature 文件是否完整,按照上文所说,bot 用这个配置计算的 request score 是 0,同样请求拦截,甚至日志中可能都看不出来什么错误。
可以看到这两种情形都差不多,甚至如果按照 fail fast 的策略,日志中会有明显的 500 错误,我不知道 Cloudflare 是否做了错误监控,因为按理来说这种级别的错误是非常明显的,需要立即报警。
很多人都集中讨论在这里的 unwrap:
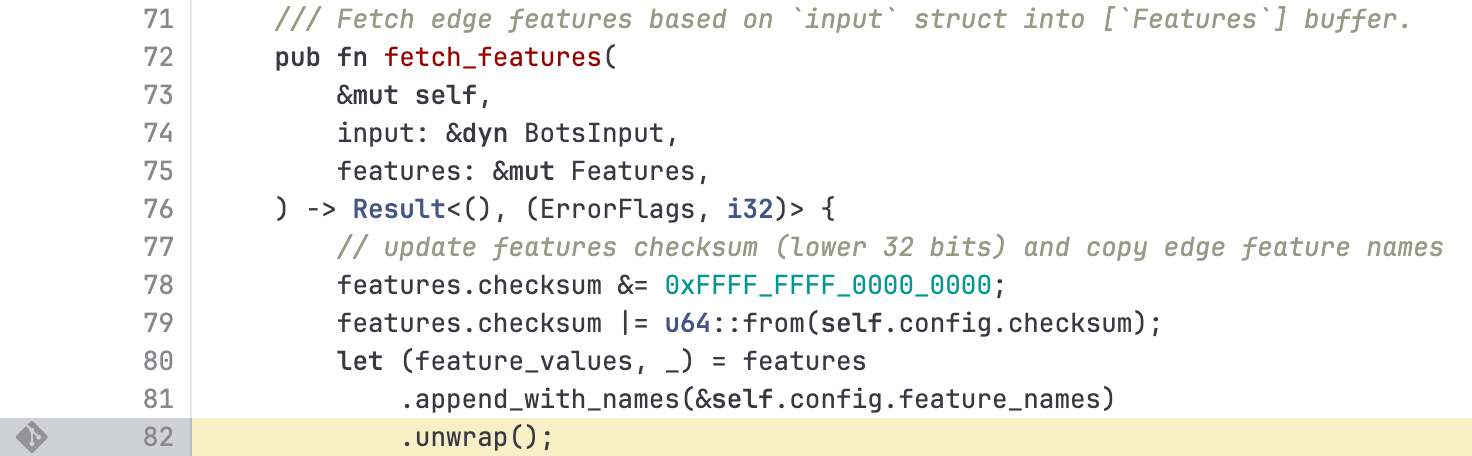
当然这不是最佳实践,但这时候即使使用 .expect("invalid bots input") 这样的写法也好不到哪里去,同样会 500 错误,只是日志里面多留一条错误信息。因为如果不监控错误码,是没人立即发现问题所在的。
更好的做法是对输入进行严格校验,例如检查特征数量和大小。如果不符合预期,应保留旧配置并拒绝加载新数据,而不是加载到一半才发现尺寸异常,更不应该没有 fallback 机制。
当然这里代码没有完全开源,我们从短短的代码片段无法了解整个项目的场景。
从这个经典的错误我们应该发现的是更高维度的警戒,开发管理和运维上有这些问题:
- 整个配置的更新居然没有灰度发布,比如你模型更新了应该是先同步到 5% 的节点,如果没有问题再继续同步到 20% 的节点,如果没问题再继续。如果有灰度更新,这次的事故不会造成这么大范围的影响,因为在早期应该就观察到了。即使是微软新版本操作系统的发布,都是会分成好几个阶段,比如 ring0, ring1 通常内部团队更新,这样问题就现在暴露在自家团队上。
- 整个配置没有 fallback 机制或者全局开关,现在发现了问题,应该有一个安全的控制开关把配置切换到上一个能工作的配置。
- 监控不到位,关键组件的 500 错误可以说是救命的警告,但从他们的排查过程上看花费了更长的时间在是否是攻击。
- 应该是没有 fuzzing 测试,这种 input 非法的情况甚至需要在单元测试和集成测试中体现。
Rust 过去天天宣传“一旦学会 rust,即便是新手也能写出健壮安全的代码”,而真的出现问题了,又开始指责写代码的人是菜鸟。
Cloudflare Rewrote Their Core in Rust, Then Half of the Internet Went Down
这里有点混淆视听,因为 Rust 所说的要解决的安全问题是内存问题,不是逻辑问题。另外,也不是因为重写导致的问题发生。
为什么 Cloudflare 要用 Rust 重写一些关键组件,可以看看他们之前的文章 Incident report on memory leak caused by Cloudflare parser bug
当然我承认在有的公司,可能有的团队完全是为了绩效或者纯个人偏好而发起重写老组件的项目。而更多公司确实是被内存安全问题折磨得怀疑人生才会去重写,像上面文中所说的安全事故是底裤被人扒了,自己还不知道,得让旁观者告诉你才发现。和这次事故的因为工程管理上所做成的安全事故有明显的分别。所以 Rust 所说的安全,是如何避免内存安全。
甚至即使是用了 Rust,一些内存上的问题还是可能因为逻辑上的错误而出现,比如我这个工作中的 PR Avoid duplicated retryable tasks就是避免往队列里加了重复的 task 而造成内存用得越来越多。
这次 Cloudflare 的事故就比如一个司机驾驶沃尔沃,结果碰上了山体滑坡被压死了,这种场景下就是换成任意其他品牌的车都会是一个结果。但如果你跑来说,看吧,沃尔沃号称安全,结果还不是一样死,这叫做虚假宣传。
这不叫虚假宣传,而是你对车有了不切实际的幻想。沃尔沃确实不完美,但每个人都会有不同的选择偏好。正常人理解沃尔沃说的安全是大部分场景下、对比其他车会安全一点,而不是说买了沃尔沃就会长生不老了。
永远记住:No Silver Bullet。
总之,这次 Cloudflare 的事故虽然造成的影响挺大,但这个公司也确实足够公开透明,事故分析写得非常清晰,值得大家学习并反思自己组织上有没有类似的工程问题。
