CKB 相关技术文章第三篇。
背景
CKB 的每一个交易在提交到交易池之前都会经过一个 script verification 的过程,本质上就是通过 CKB-VM 把交易里的 script 跑一遍,如果失败了则直接 reject,如果通过了才会继续后面的流程。

这里的 script 就是一种可以在链上执行的二进制可执行文件,也可以称之为 CKB 上的合约。它是图灵完备的,我们通常可以通过 C、Rust 来实现这些 script,比如 nervosnetwork/ckb-system-scripts 就是 CKB 上的一些常用的系统合约。用户在发起交易的时候就设置好相关的 script,比如 lock script 是用来作为资产才所有权的鉴定,而 type script 通常用来定义 cell 转换的条件,比如发行一个 User Define Token 就需要指定好 UDT 所对应的 type script。script 是通过 RISC-V 指令集的虚拟机上运行的,更多内容可以参考 Intro to Script | Nervos CKB。
大 cycle 交易的挑战
通常一个简单的 script 在 CKB-VM 里面执行是非常快的,VM 上跑完之后会返回一个 cycle 数目,这个 cycle 数量很重要,我们用来衡量 script 校验所耗费的计算量。一个合约的 cycle 数多少,理论上来说依赖于 VM 跑的使用用了多少个指令,这由 VM 在跑的时候去计算 VM Cycle Limits。
随着业务的复杂,逐渐出现了一些大 cycles 的交易,跑这些交易可能会耗费更多的时间,但我们总不可能让 VM 一直占着 CPU,比如在处理新 block 的时候,CPU 应该在让渡出来。但之前 CKB-VM 对这块的支持不够,为了达到变相的暂停,处理大 cycles 的时候我们可以设置一个 step cycles,假设我们设置为 100 cycles,每次启动的时候就把 max_cycles 设置为 100,这样 VM 在跑完 100 cycle 的时候会退出,返回的结果是 cycle limitation exceed,然后我们就知道这个 script 其实是没跑完的,先把状态保存为 suspend,然后切换到其他业务上做完处理之后再继续来跑。回来后如何才能恢复到之前的执行状态呢,这就需要保存 VM 的 snapshot,相当于给 VM 当前状态打了一个快照:
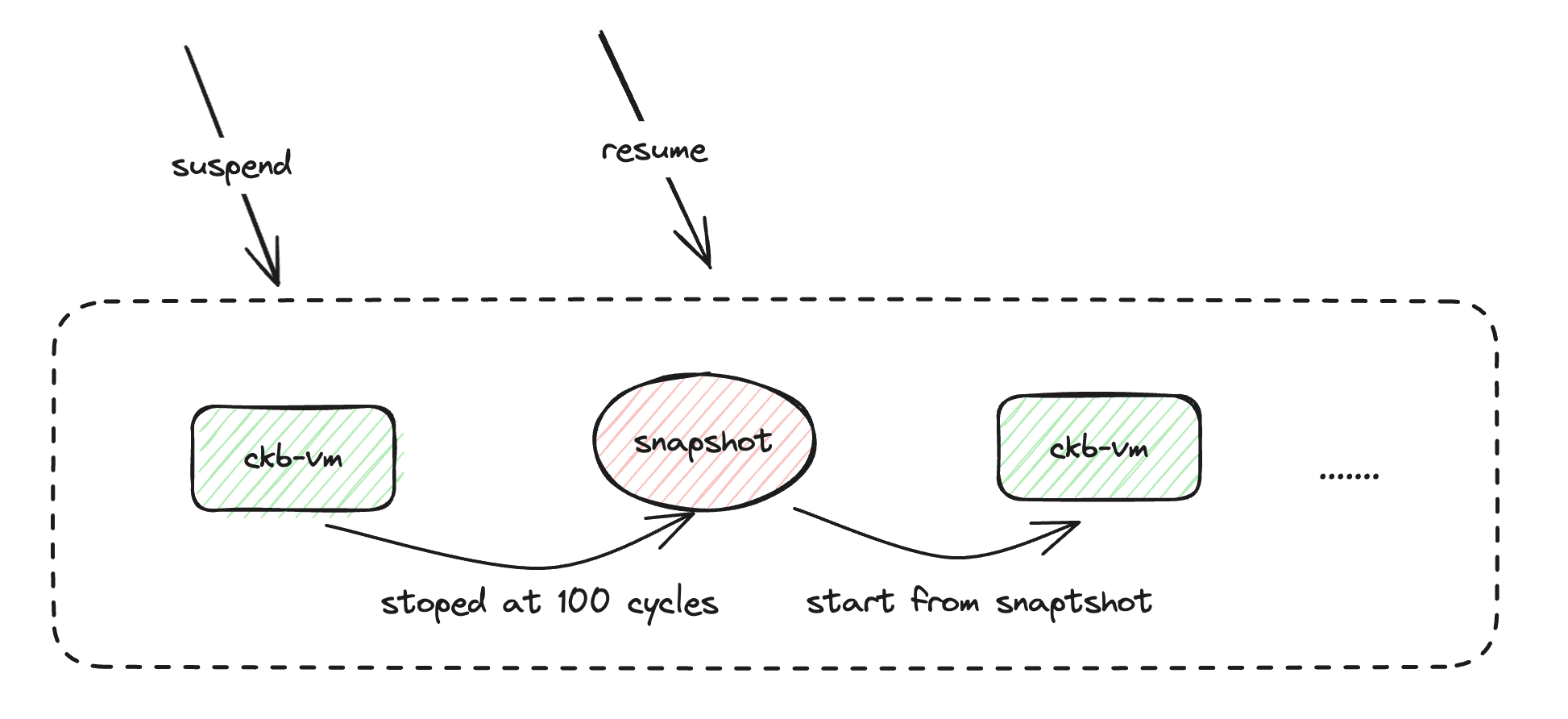 根据这个机制,我们老的 script 校验大交易的整个流程是通过一个 FIFO 的队列保存大交易,然后通过一个后台任务不断地从这个队列中取交易跑 VM,每次都跑 1000w cycle 左右,在这个过程中就可能切换出去,没跑完的交易继续放入队列等待下一次执行:
根据这个机制,我们老的 script 校验大交易的整个流程是通过一个 FIFO 的队列保存大交易,然后通过一个后台任务不断地从这个队列中取交易跑 VM,每次都跑 1000w cycle 左右,在这个过程中就可能切换出去,没跑完的交易继续放入队列等待下一次执行:

对应到代码就是 ChunkProcess 这个单独服务来处理的。由于 ChunkProcess 是一个单独的服务,它的处理流程和其他交易的处理流程是不一样的,这样会导致代码的复杂度增加,比如:
- 要针对 ChunkProcess 里面的交易额外判断,例子 1, 例子 2
- 暂停 / 恢复 ChunkProcess 处理的时候,需要对 ckb-vm 做相关的状态保存和恢复处理,参考结构 TransactionSnapshot, 代码比较复杂且容易遗漏,历史上也有过相关的 bug 1, bug 2, 以及安全问题。
- 代码中包含重复逻辑,比如
chunk_process里的process_inner和_resumeble_process_tx。 - 由于它只能同时处理一个大 cycle 交易,在 tx pool 本身比较空闲的情况下如果收到了多个大 cycle 交易也不能并行处理,比如 .bit 团队之前有过反馈他们通过本地 rpc 同时提交多个大 cycle 交易会比较慢的问题。
CKV-VM pause
这些问题的根本是 VM 只能通过 cycle step 的方式来暂停,有没有一种方式是我们任何时候想暂停就暂停,就是 event based 的方式。所以后来 CKB-VM 团队做了一些改进:
- ckb-vm 新的暂停方式
- feat: Add alternative snapshot design. #345
- Make ckb-vm thread-safety #299
- CKB feature: thread-safe vm
这个方法的本质是通过 VM 的 set_pause 接口,把一个 Arc<AtomicU8> 的 pause 共享变量设置给 VM。然后在 VM 外通过更新这个 pause 的变量让 VM 进入暂停状态或者继续执行,这样我们就不需要 dump snapshot 等操作,因为 VM 整个就还是在内存中等着:

新的实现方案
基于这些改进我们可以重新设计和实现 CKB verify 这部分的代码,主要是为了简化这部分代码,并且提高大交易处理的效率。这是一个典型的 queue based multiple worker 方案:
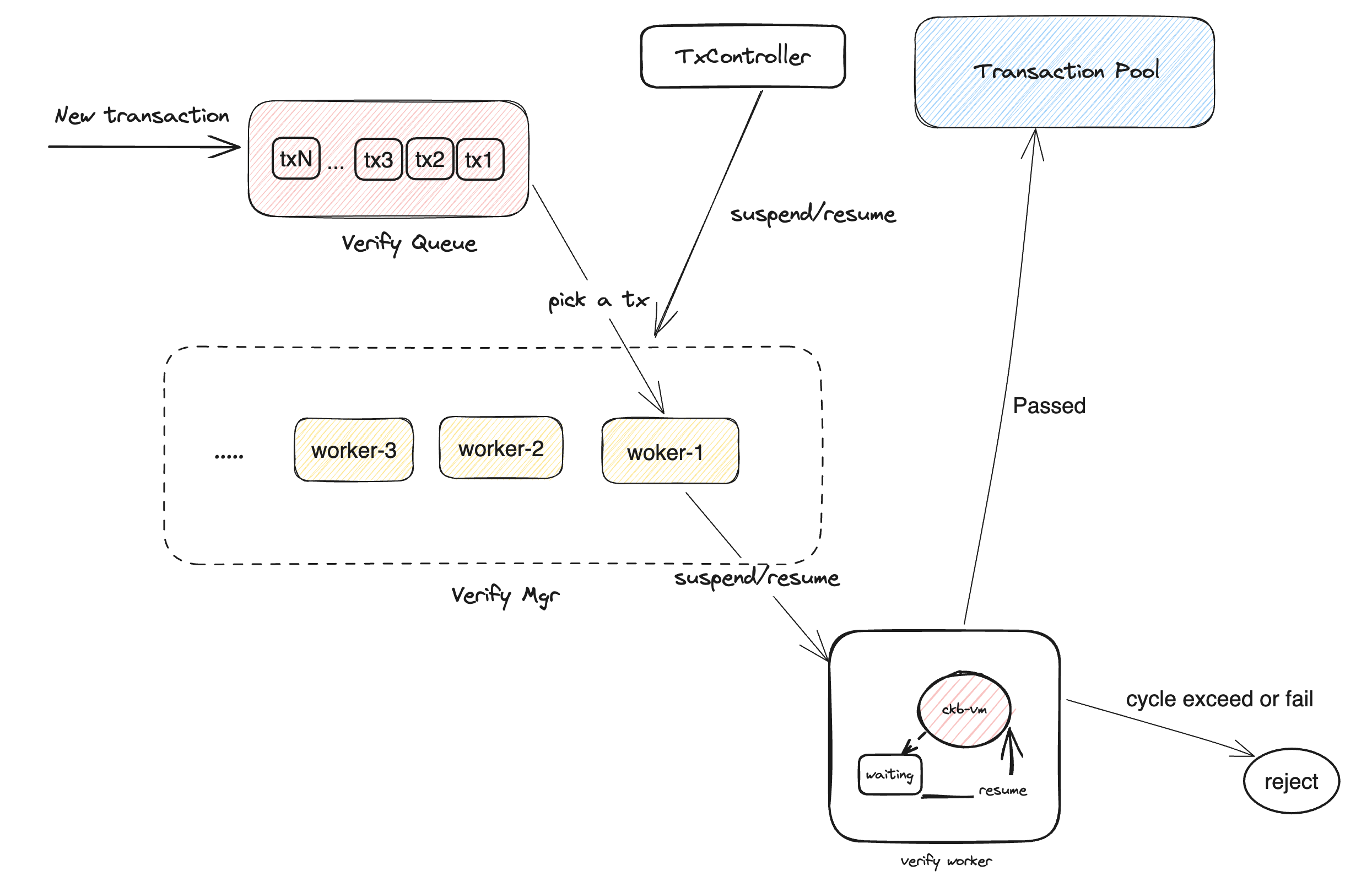
主要的核心是就是这段异步执行 VM 的逻辑:chunk_run_with_signal。做的过程中发现一些其他问题:
- 交易提交的时候,
SubmitLocalTx和SubmitRemoteTx如果 verify 失败目前会立即返回Reject,如果改成加入队列的方式,这个结果无法实时给到,所以做了如下改动:- 优先处理本地的交易,本地提交的交易不会放入 queue,而是直接会在 RPC 的处理阶段执行
- 所有的来自网络 peer 的交易都全到放入到 queue
- 后来 CKB vm 又新增了 spawn 的实现,所以会有 parent、child 的概念,那么
Child VM是执行 syscall 的时候执行machine.run,如果不改这块执行 child vm 的时候不可暂停- 后来我们讨论了之后决定 spawn 时把父的
Pause传递给子,然后暂停的时候给父的Pause设置暂停,这样所有的子 machine 同样返回VMError::Pause,同时把当前的 machine 栈重新入栈,恢复的时候继续执行,这里逻辑比较重,相关代码实现:run_vms_child。
- 后来我们讨论了之后决定 spawn 时把父的
- 后来用重新设计了 spawn,使用了一种新的 determined scheduler 的方式去管理所有的 vms 和 IO,之前和 VM 的使用者角度来说之前需要和 VM 交互,现在变成了都通过 scheduler 来管理。关于 spawn 的设计参考这个文档:Update spawn syscalls。
整个 PR 在这里:New script verify with ckb-vm pause
