在 11.9 号清迈的 CKCON 会议上我会做一个关于 CKB 交易池的演讲,这是我准备的 slides Key Upgrades of the CKB Core 。所以这段时间在整理之前做项目的时候写的一些文档,顺便分享到自己的博客上。既然我们整个项目的源码都是公开的,这些文档其实也是可以分享的。
第一次听说 CKB 的读者可以参考这个文档以了解什么是 CKB 以及如何工作的:How CKB Works | Nervos CKB。
我加入 Cryptape 之后一年内做的主要工作,涉及到交易池重构、Replace-by-fee 功能、以及 new-verify。这是第一篇关于交易池重构的文章。
什么是交易池
在 bitcoin 中交易池叫作 mempool,比如 mempool - Bitcoin Explorer 这个网站就很好地展示了其当前的状态。
交易池是 bitcoin 中的一个重要的组件,但感觉专门关于这块的资料很少,只能通过 PR 和邮件列表上的讨论看到一些文档。但交易池非常重要,因为一个交易要上链必须会通过交易池,而其中的交易打包算法涉及到如何选择合适的交易,这里面有很多因素需要考虑,所以在实现上也是比较复杂的。
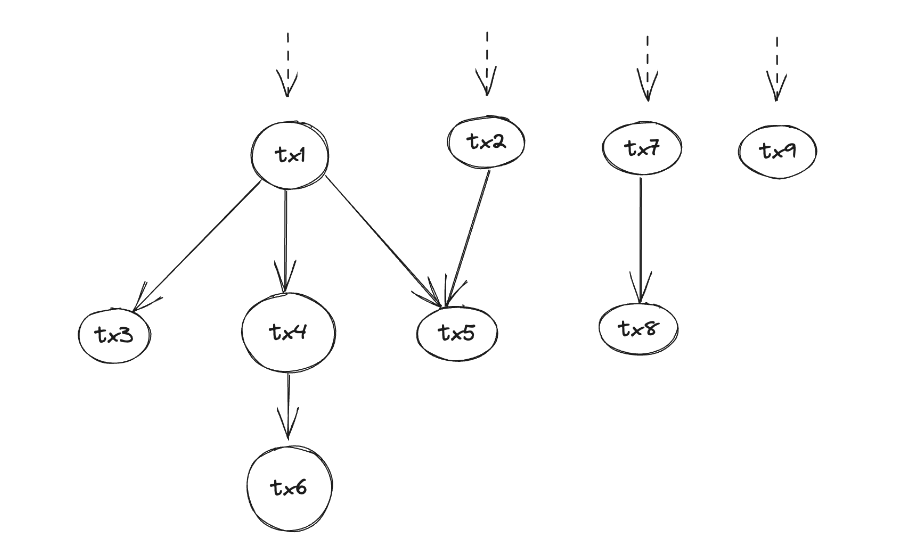
当一个交易被提交到一个节点时,或者一个节点从网络中同步到交易时,这个交易首先需要被加入到交易池中,交易池里会根据一定的算法去选择下一个需要被打包的交易,另外交易池作为一个缓存,我们需要为其设置一个最大的 size。所以交易池里面最重要的两个操作就是 packaging 和 evicting。
交易池里面的交易存在父子关系,打包的时候需要从交易链的纬度去考虑,后面的 Replace by fee 这些功能也需要关注整个交易的所有子交易。
交易池重构
问题
根据 RFC consensus-protocol 的设计,CKB 里的 tx-pool 采用了两段提交的方式:
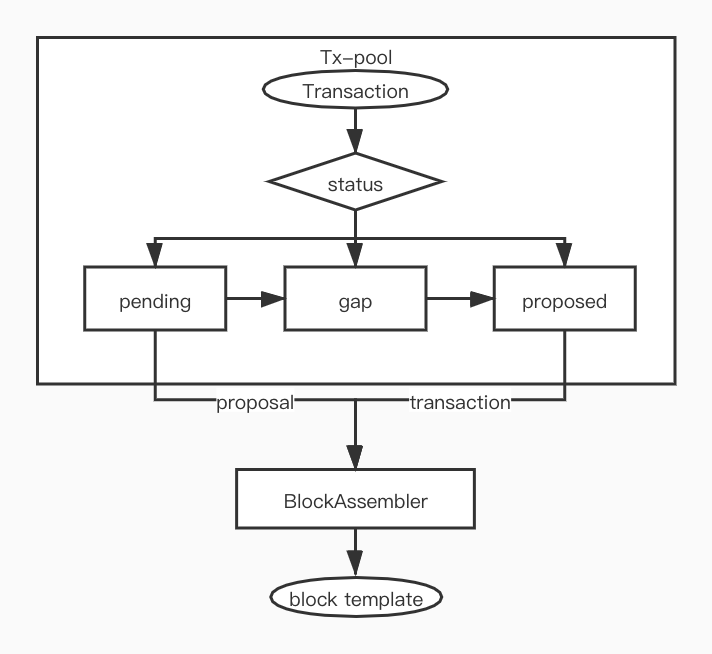
相应地在交易池最初实现的时候, ckb 的代码实现中 tx-pool 同样采用了三个独立的队列,具体定义如下:
pending交易刚加入到交易池时候的状态,我们每次只能处理不多于MAX_BLOCK_PROPOSALS_LIMIT个交易,交易需要先进入gap备选,具体代码逻辑在 update_proposals 。gap已经被 proposed 了,但是还不能被打包,需要等一个块后才能被打包,所以这只是内部中间过渡状态。proposed交易可以加入到block_template.transactions, 最终打包到 block 里,具体代码逻辑在 block_assembler。
实现中 pending 和 gap 同样都是使用了 PendingQueue(LinkedHashMap),而 proposed 采用了 SortedTxMap(HashMap + BTreeSet) :
pub struct TxPool {
pub(crate) config: TxPoolConfig,
/// The short id that has not been proposed
pub(crate) pending: PendingQueue,
/// The proposal gap
pub(crate) gap: PendingQueue,
/// Tx pool that finely for commit
pub(crate) proposed: ProposedPool,
....
pub(crate) expiry: u64,
}
这样的实现存在以下问题:
-
我们不容易对所有在交易池中的 entry 做统一排序,这样会存在以下问题:
- 一个 fee 高的交易可能在 transaction 多的情况下在 pending 阶段一直卡着,因为我们在 pending 和 gap 阶段只是按照时间顺序来处理,只在 proposed 后的打包阶段按照交易费来处理。
- issue 3942 交易池满了之后,我们需要选择一些 entry 做 evict,我们目前的 evict 逻辑很简单粗暴。我们希望尽量选择最小 descendants 的交易,这样能避免在 evict 过程中删除过多交易。我们目前在 pending 和 gap 阶段没有记录 descendants,而需要加入这个逻辑就和 proposed 阶段完全重复,而且因为不会统一排序,后续实现也不容易。
-
pending, gap 和 proposed 除了所采用的数据结构不同外,有很多逻辑雷同的代码,比如 entry 的新增和删除等操作,同样都维护了 deps 和 header_deps,resolve_conflict, resolve_conflict_header_dep, resolve_tx 等函数的逻辑也是类似的,但实现上有些细微差异,这导致长期来说代码不容易维护。
-
同样我们在
tx-pool上对 entry 做迭代和查询时,需要依次针对 pending, gap, proposed 做相同的逻辑,比如 resolve_conflict_header_dep 这样的函数在 pool 中有几个类似的,甚至 get_tx_with_cycles 这样的函数,需要依次判断各个队列。 -
实现其他功能不方便,比如我们如果要实现 Replace by fee,就需要找交易池中和新交易有冲突的交易,我们需要在三个数据结构上分别进行检查才能得到结果。
方案
基于以上解决现有问题、应对未来的潜在需求、保持代码可维护性的角度,同时参考 Bitcoin txmempool 的实现,我们提出引入 Multi_index_map 对 tx-pool 进行重构。
总体方向是把所有的 entry 放入统一的数据结构中进行管理,加入一个新的字段 status 标识目前 entry 所处的阶段,然后通过 index_map 的方式根据不同的属性进行排序和迭代:
pub enum Status {
Pending,
Gap,
Proposed,
}
#[derive(MultiIndexMap, Clone)]
pub struct PoolEntry {
#[multi_index(hashed_unique)]
pub id: ProposalShortId,
#[multi_index(ordered_non_unique)]
pub score: AncestorsScoreSortKey,
#[multi_index(ordered_non_unique)]
pub status: Status,
#[multi_index(ordered_non_unique)]
pub evict_key: EvictKey,
// other sort key
pub inner: TxEntry,
}
其中根据 Rust 社区的 multi_index_map 内部实现采用的数据结构看,性能上应该没有什么大问题:
- Hashed index retrievals are constant-time. (FxHashMap + Slab).
- Sorted indexes retrievals are logarithmic-time. (BTreeMap + Slab).
- Non-Unique Indexes
- Hashed index retrievals are still constant-time with the total number of elements, but linear-time with the number of matching elements. (FxHashMap + (Slab * num_matches)).
- Sorted indexes retrievals are still logarithmic-time with total number of elements, but linear-time with the number of matching elements. (BTreeMap + (Slab * num_matches)).
- Iteration within an equal range of a non-unique index is fast, as the matching elements are stored contiguously in memory. Otherwise iteration is the same as unique indexes.
具体实现时我们是否把 inner 也放在 Slab 里面以后可以通过 benchmark 来选择,从实现的简洁性角度考虑统一放在一个数据结构里面更容易。
目前的实现版本:Tx pool rewrite with multi_index_map #3993
实现结果
我们首先只是做模块内的重构 (保持对外逻辑和以前一样),当然考虑引入了新的数据结构,不管是从性能上还是内存占用上都会有一些影响。
为了做统一排序这件额外的事,本质上我们引入了额外的 Map(FxHashMap 或 BTreeMap) 来存储,所以比以前需要更多内存。另外,我们有时候需要调用 get_by_status 来筛选某个状态的 entries,这在新的实现里面需要先从 index 里面找出 slab 的 id,然后再找到对应的 entry,所以必然也会比以前慢。
从最终的性能对比结果上,除了内存会稍微有增加,性能上没有大的变化。另外我们在实现的过程中对所用到的 Rust 包 multi-index-map 做了一些贡献:Non-unique index support, capacity operations, performance improvement & more by wyjin
