周末在和一个日本小伙一直讨论一个 Obsidian 的 补全插件,经过一个周末的努力,最终这个插件完善了不少。我主要想用这个插件来补全英文输入,这个插件目前没有自带的词典。我在互联网上搜索了一圈,最终在 Github 上找了这个 Google 10000 English,也就是最长使用的搜索单词。
实际上,前 7000 个英语单词覆盖了日常的 90% 使用场景。
中文输入
首先我碰到的问题是,输入中文的时候插件也在补全英文。然后我提了第一个 issue。作者很快就回复了,给了我一个开发版本尝试,很完美的修复了这个问题。
然后在使用过程中发现另一个小问题,比如我的字典里面有 apple,但是如果我是在句子头部输入 Ap ,这个单词并没有出现在补全列表。我们当然可以把字典的单词都进行首字母大写的处理,但是这就会让字典翻倍。
我看了看源码,果然如自己猜想的那样,匹配的时候没有考虑首字母大写的问题。我花了一些时间做了一个 PR:fix issue #30, take care of uppercase 。
性能优化
在我做上个修复的时候,也顺便修复了一个性能上的问题,看这个补全插件的核心算法如下:
function suggestWords(words: Word[], query: string, max: number): Word[] {
return Array.from(words)
.filter((x) => x.value !== query)
.map((x) => {
if (caseIncludesWithoutSpace(x.value, query)) {
return { word: x, value: x.value, alias: false };
}
const matchedAlias = x.aliases?.find((a) =>
caseIncludesWithoutSpace(a, query)
);
if (matchedAlias) {
return { word: x, value: matchedAlias, alias: true };
}
return { word: x, alias: false };
})
.filter((x) => x.value !== undefined)
.sort((a, b) => {
const aliasP = (Number(a.alias) - Number(b.alias)) * 10000;
const startP =
(Number(lowerStartsWith(b.value!, query)) -
Number(lowerStartsWith(a.value!, query))) *
1000;
const lengthP = a.value!.length - b.value!.length;
return aliasP + startP + lengthP;
})
.map((x) => x.word)
.slice(0, max);
}在这个函数中如果词典列表很长,这里的 filter, map, filter 会遍历列表三次,是很耗时的操作。我把第一个 filter 干掉了。然后在匹配逻辑里面增加了首字母大写的相关的 处理。除了自定义的单词词典,这里补全的候选词来源包括当前文件内容、Obsidian 的内部链接。而链接需要进行部分匹配进行补全。
后续在使用过程中我又觉得补全有些慢,甚至会影响输入的体验,在 Obsidian 里面通过 Ctrl+Shift+I 可以打开调试面板,我们可以看到补全的耗时: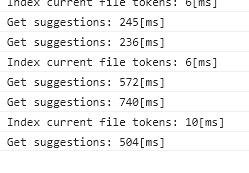
这里的主要问题还是因为每次输入一个字母,算法都在遍历单词列表两边。优化思路有两条:
- 使用类似桶排序的思路,把单词按照首字母进行分割,分成 26 个子列表,这样查找的时候就先根据首字母找到子列表,然后进行遍历搜索。
- 使用类似 Trie Tree 的数据结构进行前缀匹配。
后来那个作者按照第一种思路进行了 优化,很快将补全时间优化到了 0~5 ms。果然粗暴的算法其实很多时候就够了。
中文分词
在日常使用过程中,我又发现了还存在这个 问题。如果我尝试去修改中文句子的某个部分,这个插件会补全当前句子,就像这样: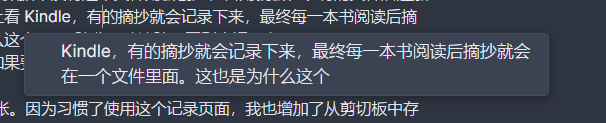
这当然是完全没有意义的。我看了一下代码发现是没有进行中文分词,所以现在的补全把这个中文句子当作一个连续的字符串在补全。
我自己尝试这想做一个 PR,但是没找到合适的中文分割 JavaScript 库。Obsidian 不能使用 Node 的库(移动端方面的考虑),所以也就不能使用这个 NodeJieba。虽然还没完成这个分词功能,不过我也在这个过程中学着写了点 TypeScript。
一些感想
这个看似简单的功能,如果要做到日常可用其实有很多细节需要完善。这个算法问题看起来不难,很适合用来进行面试,因为这是日常中很常见的一个需求场景,而且优化这个算法思路也可以很开放。
TypeScript 真强,虽然我只是简单用了一下,一些常见的 JavaScript 错误比如 enum 忘记补全之类的问题都能找出来。Electron 真猛,VSCode、Obsidian、Slack 这类工具都是 Electron 开发的。
开源软件的好处在于很多代码的作者对自己的成果有一种成就感,所以会想办法来完善,而用户也可以帮着来想办法。在这个过程中,不仅可以让其他人受益,自己也得到了一些学习和提高😘。
