问题
Kong 在实践中会有一些疑惑的地方,这里记录一下。注意这里记录的 Kong 集群部署的问题是 0.10.3 版本的,最新 Kong 版本已经不是通过 serf 来管理不同节点之间的配置同步问题。
在 Kong 多节点部署的时候,有时候某个节点停掉后,我们在后台可以看到 left 的信息,而且这个 left 信息会保留一段不短的时间。类似于如下:
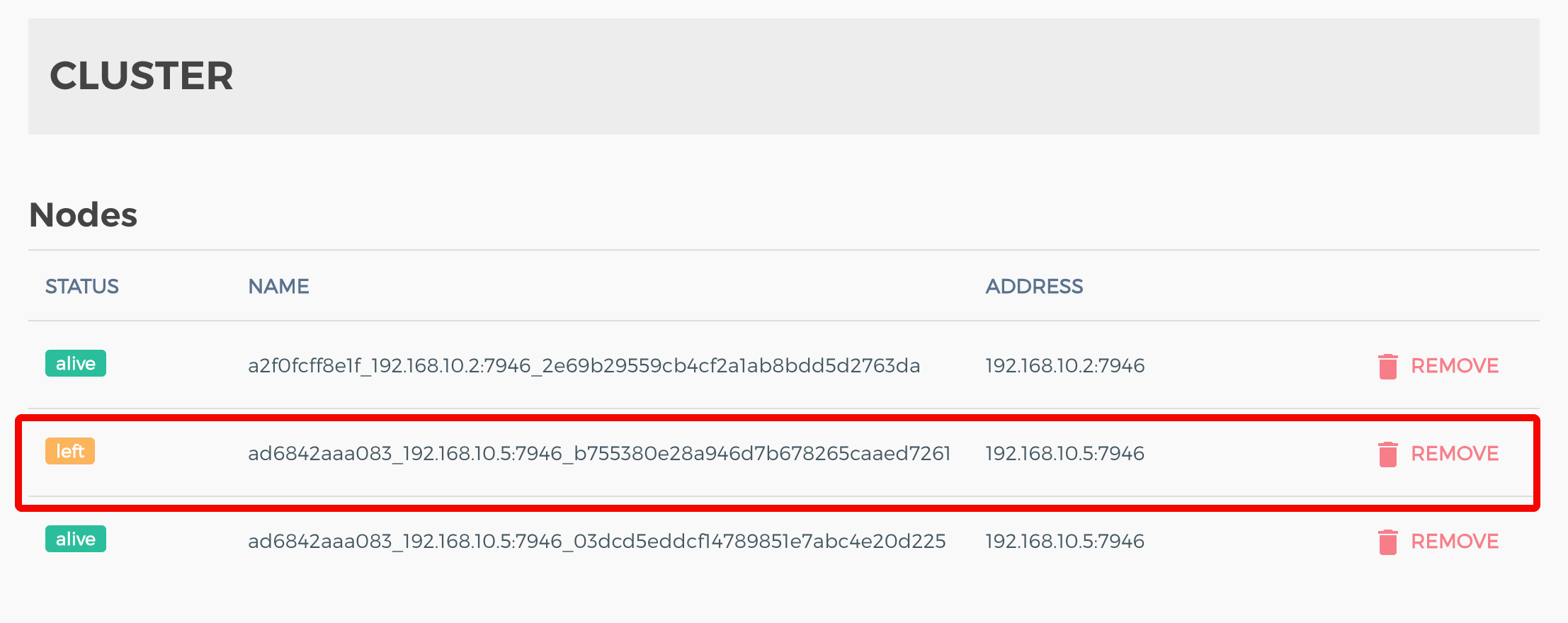 kong-left
kong-left
分析
管理后台 Konga 是通过 api 获取的节点信息,在kong/kong/api/routes/cluster.lua文件里可以看到如下路由处理逻辑:
GET = function(self, dao_factory, helpers)
local members, err = singletons.serf:members()
if err then
return responses.send_HTTP_INTERNAL_SERVER_ERROR(err)
end
local result = {data = {}}
for _, v in pairs(members) do
if not self.params.status or (self.params.status and v.status == self.params.status) then
table_insert(result.data, {
name = v.name,
address = v.addr,
status = v.status
})
end
end
result.total = #result.data
return responses.send_HTTP_OK(result)
end,具体serf:members()的实现在 serf.lua 里面可以看到,就是执行了serf cluster members命令获取结果然后返回 JSON。所以我们在服务器上执行这个命令其实也可以看到类似的结果:
 kong-left-cmd
kong-left-cmd
那么问题的根源当然是在 Serf 本身里面,通过看文档发现原来确实是有一定延迟的。
Serf keeps the state of dead nodes around for a set amount of time, so that when full syncs are requested, the requester also receives information about dead nodes. Because SWIM doesn’t do full syncs, SWIM deletes dead node state immediately upon learning that the node is dead. This change again helps the cluster converge more quickly.
serf 的具体实现
接着稍微看了一下 Serf 的代码,果然 Go 的项目代码直观好读。在 Serf 这个结构体里面保存了一个 leftMembers 的状态列表,每次收到 left 事件的时候处理逻辑是:
// handleNodeLeaveIntent is called when an intent to leave is received.
func (s *Serf) handleNodeLeaveIntent(leaveMsg *messageLeave) bool {
..................
// State transition depends on current state
switch member.Status {
case StatusAlive:
member.Status = StatusLeaving
member.statusLTime = leaveMsg.LTime
return true
case StatusFailed:
member.Status = StatusLeft
member.statusLTime = leaveMsg.LTime
// Remove from the failed list and add to the left list. We add
// to the left list so that when we do a sync, other nodes will
// remove it from their failed list.
s.failedMembers = removeOldMember(s.failedMembers, member.Name)
s.leftMembers = append(s.leftMembers, member)
................
return true
default:
return false
}
}通过索引变量发现这个列表会定时通过handleReap函数更新,逻辑如下:
// handleReap periodically reaps the list of failed and left members, as well
// as old buffered intents.
func (s *Serf) handleReap() {
for {
select {
case <-time.After(s.config.ReapInterval):
s.memberLock.Lock()
now := time.Now()
s.failedMembers = s.reap(s.failedMembers, now, s.config.ReconnectTimeout)
s.leftMembers = s.reap(s.leftMembers, now, s.config.TombstoneTimeout)
reapIntents(s.recentIntents, now, s.config.RecentIntentTimeout)
s.memberLock.Unlock()
case <-s.shutdownCh:
return
}
}
}所以看起来这里相关的 Timeout 是s.config.TombstoneTimeout, 接着需要看看reap到底做了什么,这里果然是把到了一定时间间隔的节点删掉了:
// reap is called with a list of old members and a timeout, and removes
// members that have exceeded the timeout. The members are removed from
// both the old list and the members itself. Locking is left to the caller.
func (s *Serf) reap(old []*memberState, now time.Time, timeout time.Duration) []*memberState {
n := len(old)
for i := 0; i < n; i++ {
m := old[i]
// Skip if the timeout is not yet reached
if now.Sub(m.leaveTime) <= timeout {
continue
}
// Delete from the list
old[i], old[n-1] = old[n-1], nil
old = old[:n-1]
n--
i--
..........
}
return old
}那么这个时间间隔是多久呢,在serf/config.go有一个默认配置:
TombstoneTimeout: 24 * time.Hour, 其他
serf 这个软件值得好好分析一下,节点的状态同步和事件处理都是分布式软件的基础,后续继续看看这个gossip protocol based on SWIM的具体实现。另外hashicorp这个公司的开源代码和文档都非常好,值得学习一番。
