缘由
最近在工作上接触了Kong这个开源项目,因为我们内部做微服务化重构,所以导致系统相互间通信比较复杂,如果想做一些涉及各个系统的功能就很困难。比如我们前段时间实现的灰度系统就把人折腾得很惨。因为我们的设计中有一些 http header 需要在各个系统之间传递。每个项目的 Nginx 里面都用了 Lua 写一些授权逻辑,最终这些逻辑分散在各个项目的 Nginx 层,维护困难。除了灰度,其他的一些比较基础的 Nginx 层功能也是各自为政。所以我们的教训是:在做微服务化之前,需要统一的、可扩张的 API 网关。我们希望网关性能好,并且扩张性足够好。使用 OpenResty 是很自然的选择,我们希望有一层 Nginx 是所有请求都会经过的,这层 Nginx 会负责做一些基础操作,当然最重要的是做流量转发。
调研了一阵子之后,我们所面临的是两条路,一是自己写一个类似于京东 JEN的系统,在调研一圈之后我们发现 Kong 是比较适合自身业务需求的。二是在 Kong 的基础上做一些插件开发,然后集群部署 Kong 即可。
我之前稍微看了一下介绍,认为 Kong 可能对我们来说太重了些。后来又仔细看了一阵源码,自己认为代码质量挺好,而且模块化和可扩张性做得很好,因此决定采用。
Kong 简介
Kong 项目的目的是这样一幅图kong-intro:
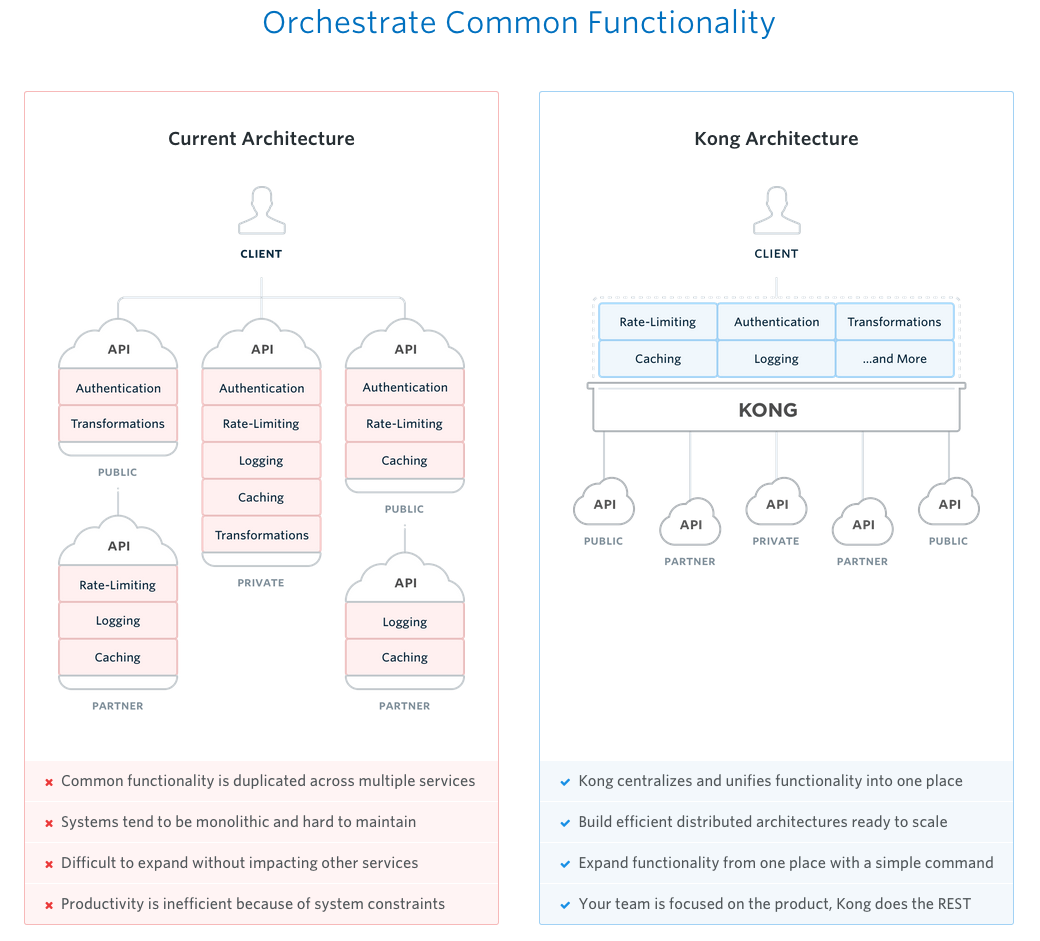
可以看到这正是我们要做的事情。使用 Kong 的优势在于:
- 可扩展性,Kong 依赖一个数据库来实现配置存储,依赖 serf 来实现 instance 之间的通信。任何一个节点修改了其他节点会收到通知并重新 reload 配置。
- 模块化,Kong 可以方便地增加新的插件,并且插件可以通过 Restful API 进行管理
主要代码模块
Kong 的使用方法这里不做介绍,这里有非常详细的文档和示例。我主要分析一下其源码和原理。
- core 目录里面是一些基础框架代码,包括 hooks,事件,插件基础
- plugins 目录包括所有 kong 自带的插件,kong 的插件扩展有一套自己的规范,按照规范来非常容易地就能扩展 kong
- dao 是数据库抽象层,目前 kong 自带支持数据库 postgresql 和 cassandra。
- tools 为一些工具函数,需要注意的是 cache。因为所有配置(包括插件的配置)都会是用 cache 来缓存,为了减少读取数据库次数。
- api Kong 会提供一个系列接口来更新配置
我觉得 Kong 的代码质量很好,另外依照带着问题来学习新东西感觉非常有收获,这几个部分我都是从一个主题问题逐个分析,这几个问题解决了之后自然对代码就熟悉了很多,并且有信心在生产环境使用。后续我会陆续继续写一些 Kong 相关原理分析,顺便更深入熟悉一下 Lua。主要涉及到 Kong 的初始化部分、缓存如何更新、插件机制如何实现等。
