一个 Rust 程序是如何从源文件编译为二进制文件的?
如果从头开始看 rustc 的源码会无从下手,我之前通过解决 issue 去读过部分模块的源码,就是 bottom-up 的方式,但我还未从整体上理解 rustc 的源码结构。
这篇文章主要是我在重看 Rust Compiler Development Guide 的一些随手记录,还有些自己的动手实验,旨在厘清编译器的大致脉络,理解每个阶段做了些什么,如果你想看更为完整的文档请参考官方的手册。
Rust 编译器分为这几个主要的阶段,回顾我目前做的工作大多集中在 MIR 之前,分阶段从前到后接触得越少 😊
整体架构
编译器是典型的输入输出系统,每个阶段都有对应的入和出。我们经常可以看到 lowering 这个术语,这个 lowering 的对象可以是源程序、AST、IR,不断地把程序中的抽象由高变低的过程,到 MIR 就已经是类似 LLVM IR 这个级别了。
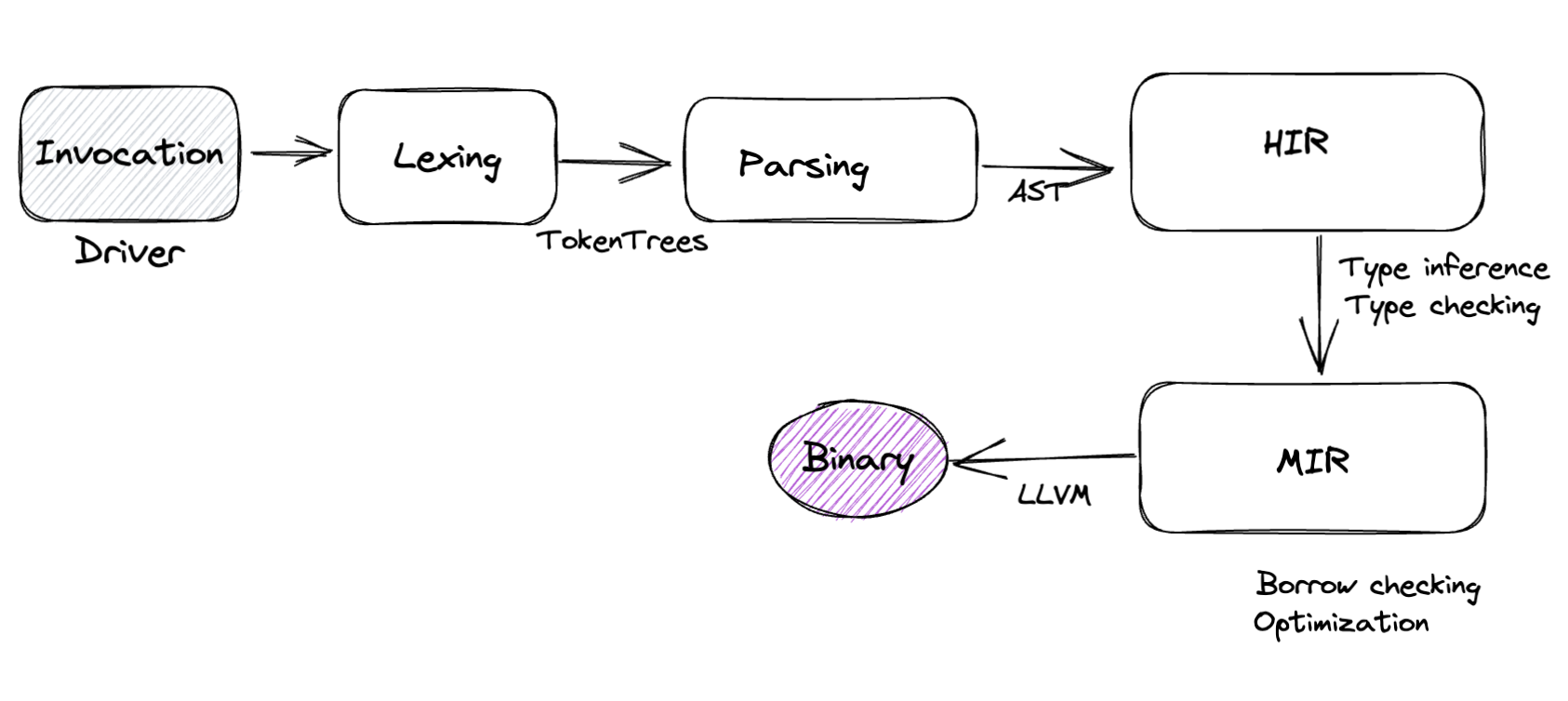
Lexing: 把源程序解析为 token 流。
Parsing: 把 token 流转换为 AST(Abstract Syntax Tree),这期间很做宏扩展、AST 验证、名称解析和早期 linting。
HIR lowering: 将 AST 转换为高级中间表示 HIR(High-level IR),这是一种对编译器更友好的 AST 表示,其中也涉及很多诸如循环和 async fn 之类的脱糖。然后我们使用 HIR 进行类型推断(type inference)、特征求解(trait solving)和类型检查(type checking)。
MIR lowering: 将 HIR 转换到 MIR(Middle-level IR),用于借用检查和其他重要的基于数据流的检查,例如检查未初始化的值。在此过程中还构建了更加脱糖的 THIR(Typed HIR),THIR 主要用于 pattern checking 检查。
Code generation: 主要基于 LLVM 做代码生成,也支持 Cranelift。
编译入口
当我们运行编译命令 rustc main.rs 时,编译器首先会通过 rustc_driver 这个最上层的组件来处理输入参数,然后调用更基础的组件来启动编译行为。
编译器的入口在于 rustc_driver::main,接着调用:
RunCompiler::new(&args, &mut callbacks).run()
真正的跑编译流程的过程在于 run_compiler,主要流程还是 Parsing,Analysising,Linking。我们看到很多调用是从一个叫做 queries 的东西开始的,比如:
queries.parse(),queries.global_ctxt()?.enter(|tcx| tcx.analysis(()))
这是 Rust 编译器的一个特点,正在从传统的 pass-based 方式转向 demand-driven,按需编译的主要思路是既然编译是典型的输入输出系统,同一个输入的输出是一样的,所以适合用缓存来减少重复计算。这是算法设计中 Memoization 的思路,详细的设计文档在 rustc-on-demand-and-incremental。
好处主要在于增量编译时加快编译速度,结果就是用户更改的少量的代码,编译速度会更快。另外一个原因是这样方便并行编译。
但目前还有很多 phase 并没有完全实现这种按需处理的方式,目前只有 HIR 到 LLVM IR 之间的步骤是查询的。我们可以在这里看到默认的 query provider:
pub static DEFAULT_QUERY_PROVIDERS: LazyLock<Providers> = LazyLock::new(|| {
let providers = &mut Providers::default();
providers.analysis = analysis;
providers.hir_crate = rustc_ast_lowering::lower_to_hir;
providers.output_filenames = output_filenames;
providers.resolver_for_lowering = resolver_for_lowering;
proc_macro_decls::provide(providers);
....
rustc_codegen_ssa::provide(providers);
*providers
});
注意这些 provider 是按照 crate 这个维度来组织的,我在日常开发中经常碰到的一个问题是,如果我切换了 compiler 的代码分支,然后直接进行增量编译,最终链接的时候报错,这大概是因为某些 crate 的代码变了,而缓存的结果是老的,重新 clean 后编译就好了,以后再排查一下具体原因。
query 引入的另外一个问题是导致错误堆栈特别长,在调试过程中经常碰到几百行的堆栈信息,我打算在这个 Issue 里尝试解决。
Lexing
Lexing 的过程和其他编译器类似,我们可以理解为给定字符串的源文件,输出一个 token 的数组。对应的代码在 compiler/rustc_lexer,这个 advance_token 就是读取下一个 token。
但是 Rust lexing 过程中的特殊点在于输出为一个称之为 token 流的东西,advance_token 被一个叫做 tokentrees.rs 的模块调用,处理后的结果是 TokenStream,其实也就是一组 Token,只是定义为一个树形的结构:
pub struct TokenStream(pub(crate) Lrc<Vec<TokenTree>>);
其定义为:
pub enum TokenTree {
/// A single token.
Token(Token, Spacing),
/// A delimited sequence of token trees.
Delimited(DelimSpan, Delimiter, TokenStream),
}
至于为什么返回的是这个树形结构,可以参考这里 What does the tt metavariable type mean in Rust macros 和 TokenTrees 简而言之就是为了处理宏。
为了看看这个 Lexing 的过程,我们可以写个简单的程序来看看中间结果:
fn main() {
let a = 1;
println!("a = {}", a);
}
在这里 parse_token_trees修改代码来把 TokenTree 打印出来:
if let Ok(ref token_trees) = token_trees {
debug!("token_trees: {:#?}", token_trees);
}
通过环境变量来把编译器运行过程中的中间结果打印出来,重定向到一个文件,运行命令:
RUSTC_LOG=debug rustc main.rs > /tmp/r.log 2>&1
我们可以看到这个程序的 TokenTree 是这样的:
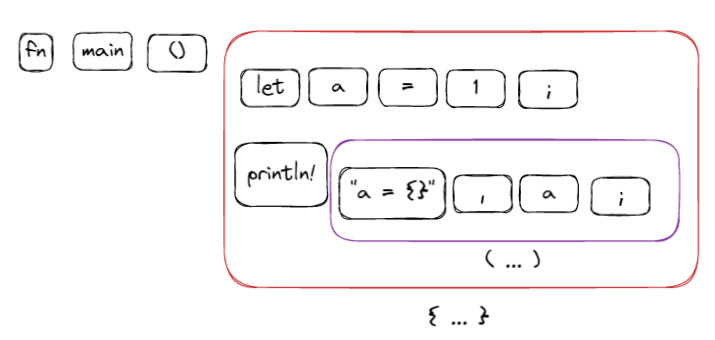
也就是通过分隔符 (...) 、{...}、[...] 把 Token 分组,我最近对这个模块做了一些改进和重构,任何分隔符不匹配的问题会报错然后终止编译,主要原因是分隔符的不匹配会让 Parser 构造出完全错误的 AST,这样诊断信息就会非常多,而大多数对开发者没有用。
Parsing
Rust 使用的手写的递归下降(自上而下)方法进行语法分析,解析是按语义构造组织的,可以在 rust/compiler/rustc_parse/src/parser 目录看到以下文件:
expr.rspat.rsty.rsstmt.rs
我们可以使用以下命令来把整个程序的 AST 打印出来,这对于编译器开发阶段比较有帮助:
rustc ./p/main.rs -Zunpretty=ast-tree > tree.log 2>&1
-Zunpretty=expanded 打印宏展开后的的 ast tree。注意 Rust compiler 是先解析 root crate,然后在宏展开后才会加载其他 submodules,为什么会这样处理:
- 宏系统需要先展开才能确定模块结构
- 支持条件编译、过程宏、动态路径
读这部代码结合 Rust Reference 会容易很多,因为 parser 很多时候就是 reference 的直译,看懂了 reference 就容易看懂 parsing。
错误处理
为什么 Rust 不用那些高级的 parsing 工具而采用手写的方式,我认为一个原因在于手写能给出更好的诊断信息,可以看到 parser 中很多代码在尝试从错误中恢复,比如用户写了下面这个程序:
const FOO: [u8; 3] = { 1, 2, 3 };
当 Parser 处理到 { 这个位置,这里看起来用户想写的是一个数组,但把 [ 写成了 {,Parser 中的这段代码会先把当前的状态存储为一个 snapshot,然后尝试 1, 2, 3 是否能 parse 成一个数组元素,如果是则能给出一个更为优化的诊断信息,如果不能则恢复到保存的 snapshot:
fn maybe_suggest_brackets_instead_of_braces(&mut self, lo: Span) -> Option<P<Expr>> {
let mut snapshot = self.create_snapshot_for_diagnostic();
match snapshot.parse_array_or_repeat_expr(Delimiter::Brace) {
Ok(arr) => {
// emit better error here
...
self.restore_snapshot(snapshot);
Some(self.mk_expr_err(arr.span))
}
Err(e) => {
e.cancel();
None
}
}
}
Parser 中很多代码都在处理类似这种逻辑。错误处理也是一个很大的话题,在 parsing 这个阶段能做的都是明显的语法层面的处理。
宏展开
在 Parsing 的过程中会遇到宏,但宏处理需要在 AST 构建之后,所以在这个过程中所有的宏会通过占位符来特殊标识。
相对 Parsing,宏展开是一个更为复杂的过程,AST 有了之后会 driver 会通过一下调用路径来逐个 crate 展开宏:
resolver_for_lowering -> configure_and_expand -> expand_crate -> fully_expand_fragment
fully_expand_fragment 这个函数是宏展开的主要算法,首先找到 AST 中的占位符,维护一个队列,然后不断地去展开直到所有的宏占位符都处理完毕,再统一加到 AST 中去,这是因为宏代码中也可能包含宏?如果某次迭代没有展开一个宏说明有语法问题。
Name resolution
Name resolution 就是解析 AST 中的所有名字,包括变量名、函数名、类型名、生命周期的命名等等。总体来说,这里也分两个阶段:
- 分两阶段:Early(宏展开期间)+ Late(展开后)
- Early 构建骨架:模块结构、导入、宏路径
- Late 填充细节:所有变量、类型、表达式的路径
在宏展开的过程中,我们只处理了 import,而并没有关注所有的名字解析,所有的命名需要等到宏展开处理了之后专门来解析名字,这也是这部分代码很多函数的名字叫做 late_*,很多逻辑在一个叫作 late.rs 的文件里。但我们并没有看到一个 early.rs 的文件,因为被拆分成了三个文件:build_reduced_graph.rs, macros.rs 和 imports.rs。
我们来写个程序包含一个明显的变量 a 未定义:
fn main() {
println!("{}", a);
}
编译器在编译的过程中肯定会报错,使用以下命令来把第一个错误信息当作一个 bug,这样我们就可以获得这个报错的调用堆栈,这是调试编译器一个很有用的小技巧:
rustc ./p/main.rs -Z treat-err-as-bug=1
通过查看堆栈我们可以看到错误是在这里出现的,因此我们找到了 name resolving 的入口在resolve_crate:
/// Entry point to crate resolution.
pub fn resolve_crate(&mut self, krate: &Crate) {
self.tcx.sess.time("resolve_crate", || {
self.tcx.sess.time("finalize_imports", || self.finalize_imports());
EffectiveVisibilitiesVisitor::compute_effective_visibilities(sel ...
self.tcx.sess.time("late_resolve_crate", || self.late_resolve_crate(krate));
self.tcx.sess.time("resolve_main", || self.resolve_main());
self.tcx.sess.time("resolve_check_unused", || self.check_unused(krate));
self.tcx.sess.time("resolve_report_errors", || self.report_errors(krate));
self.tcx
.sess
.time("resolve_postprocess", || self.crate_loader(|c| c.postprocess(krate)));
});
// Make sure we don't mutate the cstore from here on.
self.tcx.untracked().cstore.leak();
}
其中 self.late_resolve_crate(krate) 就是按照 crate 逐个去解析里面的 name,而 self.resolve_main() 是找整个程序中是否存在 main。LateResolutionVisitor 就是用来递归地遍历 AST 里的元素,比如 resolve_local,resolve_params 等等。
这里有一个很重要的概念叫做 rib,我估计是 Rust internal block 的简称🤔,这里有各种类型的 rib,一个 rib 就是定义了一个命名空间和其对应的 binding:
pub(crate) struct Rib<'a, R = Res> {
pub bindings: IdentMap<R>,
pub kind: RibKind<'a>,
}
比如我们写代码中的一个大括号就会引入一个新的 rib,同样的一个函数或者模块的定义会引入对应的 rib。对于代码:
fn main() {
let a = 1;
{
let a = 2;
println!("{}", a);
}
}
那如何能找到在 println! 的时候所用的变量 a 呢?因为变量是可以被覆盖的,可以想象这是一个按 scope 从里往外找的过程,从代码上也可以验证这个猜想,resolve_ident_in_lexical_scope 函数就是这样实现的。
在名字解析的过程中,Rust 分别为 types、values、macros 保存了不同的命名空间,因此下面这样的代码虽然看起比较诡异但却是合法的 Rust 代码:
type x = u32;
let x: x = 1;
let y: x = 2; // See? x is still a type here.
名字解析是非常复杂的部分,光 late.rs 这个文件就有 4000 行代码了。之前我做过一个关于名字解析的 PR,当一个变量没在当前 scope 里找到的情况下尝试去 inner scope 找,如果找到则给出建议。这虽然是个不复杂的 PR,但我通过这个 PR 理解了这块的大致逻辑。
Ast validation
这个阶段没做什么特别复杂的检查,比如这种:
- no more than
u16::MAXparameters; - c-variadic functions are declared with at least one named argument;
- c-variadic argument goes the last in the declaration;
- documentation comments aren’t applied to function parameters;
AstValidator 实现了各种 check_* 函数,通过 visitor pattern 在 AST 里逐个检查对应的元素,在编译器中最常用的设计模式就是 visitor pattern ,所以在 rust_ast 里定义了这个 Visitor 的 trait:
pub trait Visitor<'ast>: Sized {
fn visit_ident(&mut self, _ident: Ident) {}
fn visit_foreign_item(&mut self, i: &'ast ForeignItem) {
walk_foreign_item(self, i)
}
fn visit_item(&mut self, i: &'ast Item) {
walk_item(self, i)
}
fn visit_local(&mut self, l: &'ast Local) {
walk_local(self, l)
}
fn visit_block(&mut self, b: &'ast Block) {
walk_block(self, b)
}
...
}
所有的自定义 Visitor 只需要实现这个 trait 就行了:
impl<'a> Visitor<'a> for AstValidator<'a> {
fn visit_attribute(&mut self, attr: &Attribute) {
validate_attr::check_attr(&self.session.parse_sess, attr);
}
fn visit_expr(&mut self, expr: &'a Expr) {
...
}
...
}
HIR
HIR 是 rustc 中使用的主要 IR,是在解析、宏扩展和命名解析之后生成的。HIR 的许多部分与 Rust 表面语法非常相似,除了 Rust 的一些表达式形式已被脱糖。例如, for 循环被转换为 loop 并且不出现在 HIR 中,这使得 HIR 比普通 AST 更易于分析。
我们可以使用以下命令来展示一个程序的 HIR :
rustc main.rs -Z unpretty=hir-tree > tree.log
我们可以看到即使一个非常简单的程序,生产的 hir 也是非常长的,因为带了很多编译器里面分析使用的字段,另外 HIR 中也带有对应的代码行,也包括 Span 等这些信息,对生成诊断非常重要。rustc_hir/src/intravisit.rs 定义了一些方便在 HIR 上遍历的 visitor。
HIR 和 AST 基本是一一对应的,所以整个转换的过程就是遍历一遍 AST,代码在 rustc_ast_lowering。注意 HIR 里的 HirId 非常重要,这个 ID 是后续使用 HIR 时候经常会用到的,所以必须是唯一的。在 lowering 的过程中通过 next_id这个函数来生成唯一的 ID。
我曾经尝试做过一个比较大的 PR 来保证父节点的 HIR_ID 一定比子节点的小,但是做到后来发现代码中的递归经常需要先创建子节点,然后再创建父节点,这样 HIR_ID 就很难保证顺序,否则代码就改得很难看。如果你感兴趣可以看看能否继续做下去 Assign HirIds in HIR traversal order。
语法糖什么的都会在这时候处理掉。
Type Inference
类型推断是自动检测表达式类型的过程,比如以下代码:
fn main() {
let mut things = vec![];
things.push("thing");
}
我们并没有显示声明 things 的类型,但是因为后续代码中往 things 里写入了一个字符串,所以 things 的类型可以推断出是 Vec<&str>。
Rust 使用的是一个改进版本的 Hindley-Milner (HM) 算法,该算法最先被实现在 ML 系的编程语言中,后来被广泛采用在各种函数式编程语言里。
这块我目前接触也比较少,记得之前做过一个 PR 尝试修复一个 type inference 的小问题,不过没做完 Extend Infer ty for binary operators,问题看起来也比较简单
pub fn myfunction(x: &Vec<bool>) {
let one = |i, a: &Vec<bool>| {
a[i] // ok
};
let two = |i, a: &Vec<bool>| {
!a[i] // cannot infer type
};
let three = |i: usize, a: &Vec<bool>| {
!a[i] // ok
};
one(0, x);
two(0, x);
three(0, x);
}
变量 two 不能被推导出来是因为 i 没有类型,虽然我们知道 a 的类型是 Vec<bool> ,但不能保证 a[i]就是 bool 类型,如果你感兴趣可以试试看能否解决。
Type inference 有其局限性,2015 年 RFC 0803-type-ascription 提出来作为补充,但这个 RFC 实现了之后一直没有稳定,最终社区又提出把这个功能给去掉,而这个工作也涉及到大量的改动:De-RFC 3307: Remove type ascription。
MIR
MIR 是比 HIR 更低层次的中间表示,从 HIR 构建。MIR 方便用于控制流分析和代码优化,其中也包括 Rust 特殊的 borrow checking。MIR 的关键特性:
MIR 的一些关键特性是:
- 基于控制流图
- 没有嵌套表达式
- MIR 中的所有类型都是完全显式的
更深入了解可以读官方的这篇文章 Introducing MIR。MIR 都是一些比较原子性的操作,离 LLVM 的 IR 比较近,所以很方便后面代码生成部分。另外为了方便做 borrow checking MIR 也会在插入一些 scope 的标签。
我们可以通过 Rust Playground 查看生成出来的 MIR,如何基于 MIR 做数据流分析可参考 MIR dataflow,在 MIR 上做 borrow checking 也会更精准,NLL(non-lexical lifetime) 就是这样解决的。
Codegen 代码生成
一直到这里为止,编译都是在做数据转换,把代码变成中间层表示,然后抽象的等级越来越低,最后把 MIR 生成 LLVM IR,然后生成二进制文件。
Rust 后端可以是 LLVM、Cranelift 或者 GCC,这些都依赖于第三方库来实现,所以需要最大程度共享一些基础代码,Rust 编译器本身有自己的 LLVM 绑定包。
在这个阶段也做了如下这些事情:
- 为范性类型替换成具体的类型
- 为具体类型生成代码称为单态化 (monomorphization)
- MIR 转换为 codegen IR
- 调用 codegen 后端生成可执行文件
代码生成的入口点是 rustc_codegen_ssa::base::codegen_crate。
总的来说,我理解 Rust 是加了些便于做静态分析的语言特性,比如 lifetime 和 borrow checking 规则,编译器内部也集成了很多静态分析功能。
当然我们只是从很高的维度去快速过了一遍,里面还有些特殊的部分很复杂但我还没开始细看,比如 trait solving 。
后续继续更新 😁。
